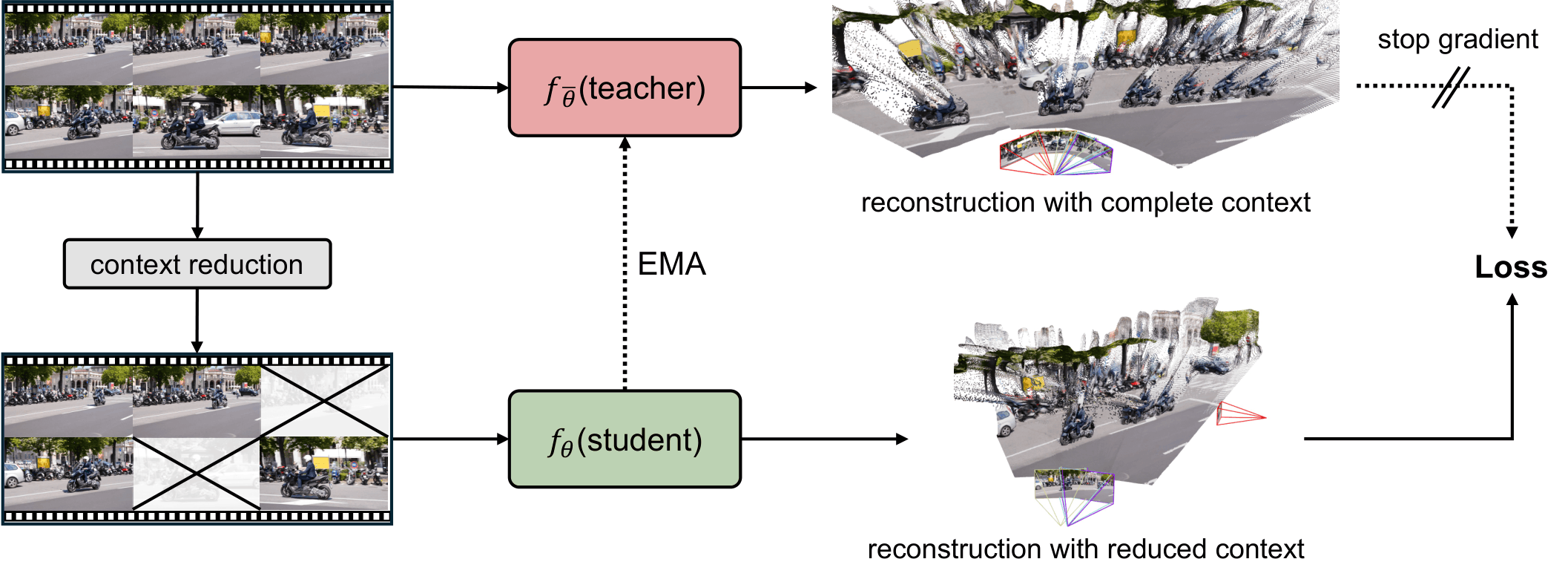
Large-scale feedforward multi-view reconstruction models have made remarkable progress, but existing approaches still rely on fully supervised training with 3D annotations. Such annotations are expensive and particularly scarce for dynamic scenes, limiting scalability. We propose SelfEvo, a self-improving framework that continually improves pretrained multi-view reconstruction models using unlabeled videos. SelfEvo introduces a self-distillation scheme using spatiotemporal context asymmetry, enabling self-improvement for learning-based 4D perception without external supervision. We systematically study design choices that make self-improvement effective, including loss signals, forms of asymmetry, and other training strategies. Across eight benchmarks spanning diverse datasets and domains, SelfEvo consistently improves pretrained baselines and generalizes across base models (e.g., VGGT and π3), with significant gains on dynamic scenes. Overall, SelfEvo achieves up to 36.5% relative improvement in video depth estimation and 20.1% in camera estimation, without using any labeled data.